| The Structure of Language | Source Code and Discussion of Newer & Better Portable Random Number Generators | |||
index |
||||
Back to Deley's Homepage | ||||
| The Structure of Language | Source Code and Discussion of Newer & Better Portable Random Number Generators | |||
index |
||||
Back to Deley's Homepage | ||||
The following is from the book
NUMERICAL RECIPES: The Art of Scientific Computing by William H. Press, et al.
There are several programming language versions of this book
available, including FORTRAN-77, FORTRAN-90, C, C++, Pascal, and BASIC. Machine
readable forms in various languages of all the sample routines
are also available if you don't want to type in the code yourself.
The code presented below is FORTRAN, but should be easily translatable
to any programming language. This is an excellent book; you should own a copy.
Also see their web site at: http://numerical.recipes/
Suppose that Ni is the member of events observed in the ith bin, and
that ni is the number expected according to some known distribution. Note
that the Ni’s are integers, white the ni’s may not be. Then the chi-square
statistic is
(13.5.1)
Any term j in (13.5.1) with 0 = nj = Nj should be omitted from the
sum. A term with nj = 0, Nj ≠ 0 gives an infinite ![]() , as it should, since in
this case the Ni’s cannot possibly be drawn from the ni’s!
, as it should, since in
this case the Ni’s cannot possibly be drawn from the ni’s!
The chi-square probability function Q(![]() |ν) is an incomplete gamma function,
and was already discussed in §6.2 (see equation 6.2.18). Strictly speaking
Q(
|ν) is an incomplete gamma function,
and was already discussed in §6.2 (see equation 6.2.18). Strictly speaking
Q(![]() |ν) is the probability that the sum of the squares of ν random normal
variables of unit variance will be greater than
|ν) is the probability that the sum of the squares of ν random normal
variables of unit variance will be greater than ![]() . The terms in the sum
(13.5.1) are not individually normal. However, if either the number of bins
is large (>>1), or the number of events in each bin is large (>>1), then the
chi-square probability function is a good approximation to the distribution of
(13.5.1) in the case of the null hypothesis. Its use to estimate the significance
of the chi-square test is standard.
. The terms in the sum
(13.5.1) are not individually normal. However, if either the number of bins
is large (>>1), or the number of events in each bin is large (>>1), then the
chi-square probability function is a good approximation to the distribution of
(13.5.1) in the case of the null hypothesis. Its use to estimate the significance
of the chi-square test is standard.
The appropriate value of ν, the number of degrees of freedom, bears some additional discussion. If the data were collected in such a way that the ni’s were all determined in advance, and there were no a priori constraints on any of the Ni’s, then ν equals the number of bins NB (note that this is not the total number of events!). Much more commonly, the ni’s are normalized after the fact so that their sum equals the sum of the Ni’s, the total number of events measured. In this case the correct value for ν is NB - 1. If the model that gives the ni’s had additional free parameters that were adjusted after the fact to agree with the data, then each of these additional "fitted" parameters reduces ν by one additional unit. The number of these additional fitted parameters (not including the normalization of the ni’s) is commonly called the "number of constraints," so the number of degrees of freedom is ν = NB - 1 when there are "zero constraints."
We have, then, the following program:
Next we consider the case of comparing two binned data sets. Let Ri be
the number of events in bin i for the first data set, Si, the number of events
in the same bin i for the second data set. Then the chi-square statistic is
(13.5.2)
If the data were collected in such a way that the sum of the Ri’s is necessarily equal to the sum of Si’s, then the number of degrees of freedom is equal to one less than the number of bins, NB - 1 (that is, KNSTRN=0), the usual case. If this requirement were absent, then the number of degrees of freedom would be NB. Example: A birdwatcher wants to know whether the distribution of sighted birds as a function of species is the same this year as last. Each bin corresponds to one species. If the birdwatcher takes his data to be the first 1000 birds that he saw in each year, then the number of degrees of freedom is NB - 1. If he takes his data to be all the birds he saw on a random sample of days, the same days in each year, then the number of degrees of freedom is NB (KNSTRN= -1). In this latter case, note that he is also testing whether the birds were more numerous overall in one year or the other: that is the extra degree of freedom. Of course, any additional constraints on the data set lower the number of degrees of freedom (i,e., increase KNSTRN to positive values) in accordance with their number.
The program is
The Kolmogorov-Smirnov (or K-S) test is applicable to unbinned distributions
that are functions of a single independent variable, that is, to data
sets where each data point can be associated with a single number (lifetime of
each lightbulb when it burns out, or declination of each star). In such cases,
the list of data points can be easily converted to an unbiased estimator SN(x)
of the cumulative distribution function of the probability distribution from
which it was drawn: If the N events are located at values xi, i = 1,...,N,
then SN(x) is the function giving the fraction of data points to the left of a
given value x. This function is obviously constant between consecutive (i.e.
sorted into ascending order) xi’s, and jumps by the same constant 1/N at
each xi. (See Figure 13.5.1).

Figure 13.5.1. Kolmogorov-Smirnov statistic D. A measured distribution of values in x
(shown as N dots on the lower abscissa) is to be compared with a theoretical distribution
whose cumulative probability distribution is plotted as P(x). A step-function cumulative
probability distribution SN(x) is constructed, one which rises an equal amount at each
measured point. D is the greatest distance between the two cumulative distributions.
Different distribution functions, or sets of data, give different cumulative distribution function estimates by the above procedure. However, all cumulative distribution functions agree at the smallest allowable value of x (where they are zero), and at the largest allowable value of x (where they are unity). (The smallest and largest values might of course be ±∞). So it is the behavior between the largest and smallest values that distinguishes distributions.
One can think of any number of statistics to measure the overall difference
between two cumulative distribution functions: The absolute value of the area
between them, for example. Or their integrated mean square difference. The
Kolmogorov-Smirnov D is a particularly simple measure: It is defined as the
maximum value of the absolute difference between two cumulative distribution
functions. Thus, for comparing one data set's SN(x) to a known cumulative
distribution function P(x), the K-S statistic is
(13.5.3)
| D = | max - ∞ < x < ∞ | |SN(x) - P(x)| |
| D = | max - ∞ < x < ∞ | |SN1(x) - SN2(x)| |
What makes the K-S statistic useful is that its distribution in the case of the null hypothesis (data sets drawn from the same distribution) can be calculated, at least to useful approximation, thus giving the significance of any observed nonzero value of D.
The function which enters into the calculation of the significance can be
written as the following sum,
(13.5.5)
The nature of the approximation involved in (13.5.7) and (13.3.8) is that it becomes asymptotically accurate as the N’s become large. In practice N = 20 is large enough. especially if you are being conservative and requiring a strong significance level (0.01 or smaller).
So, we have the following routines for the cases of one and two distributions:
Both of the above routines use the following routine for calculating the
function QKS
The incomplete gamma function is defined by
(6.2.1)
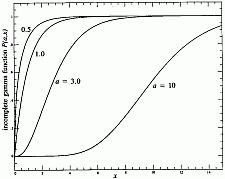
The complement of P(a,x) is also confusingly called an incomplete gamma
function,
(6.2.3)
There is a series development for γ(a,x) as follows:
(6.2.5)
A continued fraction development for Γ(a,x) is
(6.2.6)
It turns out that (6.2.5) converges rapidly for x less than about a + 1, while
(6.2.6) converges rapidly for x greater than about a + 1. In these respective
regimes each requires at most a few times √a terms to converge, and this many
only near x = a, where the incomplete gamma functions are varying most
rapidly. Thus (6.2.5) and (6.2.6) together allow evaluation of the function
for all positive a and x. An extra dividend is that we never need compute
a function value near zero by subtracting two nearly equal numbers. The
higher-level calls for P(a,x) and Q(a,x) are
The argument GLN is returned by both the series and continued fraction, procedures containing the value ln Γ(a); the reason for this is so that it is available to you if you want to modify the above two procedures to give γ(a,x) and Γ(a,x), in addition to P(a,x) and Q(a,x) (cf. equations 6.2.1 and 6.2.3).
The procedures GSER and GCF which implement (6.2.5) and (6.2.6) are
Below is function GAMMLN used by GSER and GCF above. There are a variety of methods in use for
calculating the function Γ(z) numerically, but none is quite as neat as the
approximation derived by Lanczos. This scheme is entirely specific to the gamma function,
seemingly plucked from thin air. We will not attempt to derive the approximation.
The error function and complementary error function are special cases of
the incomplete gamma function, and are obtained moderately efficiently by
the above procedures. Their definitions are
(6.2.7)
If you care to do so, you can easily remedy the minor inefficiency in ERF
and ERFC, namely that Γ(0.5) = √π is computed unnecessarily when GAMMP
or GAMMA is called. Before you do that, however, you might wish to consider
the following routine, based on Chebyshev fitting to an inspired guess as to
the functional form:
Abramowitz, Milton, and Stegun, Irene A. 1964, Handbook of Mathematical Functions, Applied Mathematics Series, vol. 55 (Washington National Bureau of Standards; reprinted 1968 by Dover Publications, New York), Chapters 6, 7, and 26.
Pearson, K (ed.) 1951, Tables of the Incomplete Gamma Function (Cambridge: Cambridge University Press).
| ALL OF THE ABOVE IS FROM THE FOLLOWING BOOK: | ||
| NUMERICAL RECIPES: The Art of Scientific Computing | ||
| William H. Press, | ||
| Harvard-Smithsonian Center for Astrophysics | ||
| Brian P. Flannery, | ||
| EXXON Research and Engineering Company | ||
| Saul A. Teukolsky, | ||
| Department of Physics, Cornell University | ||
| William T. Vetterling, | ||
| Polaroid Corporation | ||
| Cambridge University Press, 1986 | ||
| This book contains a wealth of knowledge along with source code examples on how to solve various kinds of programming problems. There are several programming language versions of this book available, including FORTRAN-77, FORTRAN-90, C, C++, Pascal, and BASIC. Machine readable forms in various languages of all the sample routines are also available if you don't want to type the code in yourself. This is an excellent book; you should own a copy. | ||
| Click here to search Amazon.com for this and similar books. | ||
| Also see thier web site at: http://www.numerical-recipes.com/index.html | ||
| The Structure of Language | Source Code and Discussion of Newer & Better Portable Random Number Generators | |||
index |
||||
Back to Deley's Homepage | ||||