
The Structure of Language
[Below is section 2-8, pp 33-40, from the book INFORMATION THEORY AND CODING by Norman Abramson,
Associate Professor of Electrical Engineering, Stanford University.
McGraw-Hill Book Company, Inc. 1963 McGraw-Hill electronic Sciences Series.]
In the previous sections of this chapter, we have defined a model
of an information source, and brought out some simple properties
of our model. It is of some interest to investigate how closely
such a model approximates the physical process of information
generation. A particularly important case of information generation
is the generation of a message composed of English words.
In this section we show how the generation of such a message may
be approximated by a sequence of successively more and more complicated
information sources.
Let us restrict ourselves to a set of 27 symbols—the 26 English
letters and a space. The simplest possible source using this alphabet
is a zero-memory source with all 27 symbols equally probable.
The entropy of this source is easily calculated.
| H(S) | = | log 27 |
| = | 4.75 bits/symbol |
A typical sequence of symbols emitted by such a source is shown
in Figure 2-6. We refer to this sequence as the zeroth approximation to English.
| ZEWRTZYNSADXESYJRQY_WGECIJJ_OBVKRBQPOZB |
| YMBUAWVLBTQCNIKFMP_KMVUUGBSAXHLHSIE_M |
|
| Figure 2-6. Zeroth approximation to English. |
Note that there is no perceptible structure to this sequence and
it is not possible to identify it as coming from any particular
language using the same alphabet. A better approximation to
English may be obtained by employing the actual probabilities
of the symbols used (Table 2-2). The entropy of a zero-memory
source with probabilities given in Table 2-2 is
| H(S) | = | 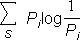 |
| = | 4.03 bits/symbol |
Table 2-2. Probabilities Of Symbols In English (Reza, 1961)
| Symbol | Probability | Symbol | Probability |
|---|
| Space | 0.1859 | N | 0.0574 |
| A | 0.0642 | O | 0.0632 |
| B | 0.0127 | P | 0.0152 |
| C | 0.0218 | Q | 0.0008 |
| D | 0.0317 | R | 0.0484 |
| E | 0.1031 | S | 0.0514 |
| F | 0.0208 | T | 0.0796 |
| G | 0.0152 | U | 0.0228 |
| H | 0.0467 | V | 0.0083 |
| I | 0.0575 | W | 0.0175 |
| J | 0.0008 | X | 0.0013 |
| K | 0.0049 | Y | 0.0164 |
| L | 0.0321 | Z | 0.0005 |
| M | 0.0198 | |
A typical sequence of symbols emitted by this source is given in
Figure 2-7.
| AI_NGAE__ITF_NNR_ASAEV_OIE_BAINTHA_HYR |
| OO_POER_SETRYGAIETRWCO__EHDUARU_EU_C_F |
| T_NSREM_DIY_EESE__F_O_SRIS_R__UNNASHOR |
|
| Figure 2-7. First approximation to English. |
Though the sequence shown here cannot qualify as good English,
it does exhibit some of the structure of the language. (Compare
this with our zeroth approximation.) The "words" of this approximation
are, for the most part, of reasonable length, and the proportion
of vowels to consonants seems more realistic. We may
improve upon the source which generated the first approximation
by using a first-order Markov source with the appropriate conditional
symbol probabilities. These probabilities are given by Pratt (1942).
| H(S) | = | 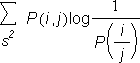 |
| = | 3.32 bits/symbol |
It is possible to generate a typical sequence of symbols out of such
a first-order Markov source by using the probabilities given in Pratt.
Shannon, however, has pointed out a much cleverer method. Ordinary
English text has the probabilities we seek contained in it.
We therefore open a book and select a letter at random, say U.
Next, we skip a few lines, read until we come to the first U and
select the first letter after the U—in this case it was R. Again we
skip a few lines, read until we come to an R, and select the next
letter. Using this procedure, we constructed a second approximation to English (Figure 2-8).
| URTESHETHING_AD_E_AT_FOULE_ITHALIORT_W |
| ACT_D_STE_MINTSAN_OLINS_TWID_OULY_TE_T |
| HIGHE_CO_YS_TH_HR_UPAVIDE_PAD_CTAVED |
|
| Figure 2-8. Second approximation to English. |
Note how the English flavor of the sequence makes itself felt
in the second approximation. We would have little trouble in
identifying this sequence as an approximation to English rather
than, say, French.
We can apply Shannon's method to construct even better approximations
to English. By selecting letters from a book according to
the two preceding letters we can construct a typical sequence from a
second-order Markov source approximating English.
| IANKS_CAN_OU_ANG_RLER_THATTED_OF_TO_S |
| HOR_OF_TO_HAVEMEM_A_I_MAND_AND_BUT_ |
| WHISSITABLY_THERVEREER_EIGHTS_TAKILLIS_TA |
|
| Figure 2-9. Third approximation to English. |
Shannon (1951) has estimated the entropy of the source corresponding
to the sequence shown in Figure 2-9 as 3.1 bits per symbol.
Using other methods, he has estimated that the entropy of English,
taking into account all the preceding text, is between 0.6 and 1.3 bits
per symbol.
It is possible to extend the process used above to generate
typical sequences out of mth-order (m ≥ 3) Markov sources having
the symbol probabilities of English. The construction of such
sequences, however, becomes impractical for m greater than 2.
Instead Shannon jumped to a zero-memory information source
with the English words rather than the English letters as the output
symbols. The probabilities of occurrence of the various words are
approximately the same as in English text. Shannon (1948)
obtained the approximation shown in Figure 2-10.
| REPRESENTING AND SPEEDILY IS AN GOOD APT |
| OR COME CAN DIFFERENT NATURAL HERE HE |
| THE A IN CAME THE TO OF TO EXPERT |
| GRAY COME TO FURNISHES THE LINE MESSAGE |
| HAD BE THESE |
|
| Figure 2-10. Fourth approximation to English. |
An even more complicated approximation to English can be
constructed by letting the probability that a given word is selected
depend upon one preceding word. The source corresponding to
this approximation is a first-order Markov source with the English
words as symbols. Shannon (1948) also constructed a typical
sequence from this type of source (Figure 2-11).
| THE HEAD AND IN FRONTAL ATTACK ON AN |
| ENGLISH WRITER THAT THE CHARACTER OF |
| THIS POINT IS THEREFORE ANOTHER METHOD |
| FOR THE LETTERS THAT THE TIME OF WHO |
| EVER TOLD THE PROBLEM FOR AN UNEXPECTED |
|
| Figure 2-11. Fifth approximation to English. |
It is interesting to note that this sequence is a reasonable approximation
to the sort of output one might expect from a very excited
and quite incoherent speaker. The fact that we can approximate
(at least to some extent), as complicated an information source
as an English speaker by the simple models of zero-memory and
Markov sources is encouraging. Many information sources found
in realistic communication problems are of a much simpler nature,
and we may expect that our models provide better approximations
to reality in those cases.
For more on creating random English sentences see
The Language Instinct: How the Mind Creates Langauge
by Steven Pinker, chapter 4: How Language Works.
A striking illustration of the differences in several Western
languages may be obtained by constructing sequences using the
statistics of these languages. We have done this for three languages,
and the sequences obtained are given in Figures 2-12 to 2-14. As
before, the first approximation corresponds to a sequence out of a
zero-memory source; the second approximation from a first-order
Markov source; and the third approximation from a second-order
Markov source.
| R_EPTTFVSIEOISETE_TTLGNSSSNLN_UNST_FSNST |
| F_E_IONIOILECMPADINMEC_TCEREPTTFLLUMGLR |
| ADBIUVDCMSFUAISRPMLGAVEAI_MILLUO |
|
| (a) First approximation to French |
| ITEPONT_JENE_IESEMANT_PAVEZ_L_BO_S_PAS |
| E_LQU_SUIN_DOTI_CIS_NC_MOUROUNENT_FUI |
| T_JE_DABREZ_DAUIETOUNT_LAGAUVRSOUT_MY |
|
| (b) Second approximation to French |
| JOU_MOUPLAS_DE_MONNERNAISSAINS_DEME_U |
| S_VREH_BRE_TU_DE_TOUCHEUR_DIMMERE_LL |
| ES_MAR_ELAME_RE_A_VER_IL_DOUVENTS_SO |
|
| (c) Third approximation to French |
| Figure 2-12. A series of approximations to French. |
| NNBNNDOETTNIIIAD_TSI_ISLEENS_LRI_LDRRBNF |
| REMTDEEIKE_U_HBF_EVSN_BRGANWN_IENEEHM |
| EN_RHN_LHD_SRG_EITAW_EESRNNCLGR |
|
| (a) First approximation to German |
| AFERORERGERAUSCHTER_DEHABAR_ADENDERG |
| E_E_UBRNDANAGR_ETU_ZUBERKLIN_DIMASO |
| N_DEU_UNGER_EIEIEMMLILCHER_WELT_WIERK |
|
| (b) Second approximation to German |
| BET_EREINER_SOMMEIT_SINACH_GAN_TURHATT |
| ER_AUM_WIE_BEST_ALLIENDER_TAUSSICHELLE |
| _LAUFURCHT_ER_BLEINDESEIT_UBER_KONN_ |
|
| (c) Third approximation to German |
| Figure 2-13. A series of approximations to German. |
| UOALNAO_NEL_D_NIS_ETR_TEGATUEOEC_S_ASU |
| DU_ZELNNTSSCASOSED_T_I_R_EIS_TAMMO_TII |
| UOEDEO_UEI_EOSEELA_NMSLAANTEC |
|
| (a) First approximation to Spanish |
| CINDEUNECO_PE_CAL_PROS_E_LAS_LABITEJAS |
| TE_ONTOMECITRODRESIO_PAY_EN_SPUSEL_LA |
| _S_UTAJARETES_OLONDAMIVE_ESA_S_CLUS_ |
|
| (b) Second approximation to Spanish |
| RAMA_DE_LLA_EL_GUIA_IMO_SUS_CONDIAS_S |
| U_E_UNCONDADADO_DEA_MARE_TO_BUERBALI |
| A_NUE_Y_HERARSIN_DE_SE_SUS_SUPAROCEDA |
|
| (c) Third approximation to Spanish |
| Figure 2-14. A series of approximations to Spanish. |
As a final example in this series, we present a series of approximations (Figure 2-15)
to another Western language and leave it to the reader to determine which language.
| ETIOSTT_NINN_TUEEHHIUTIAUE_N_IREAISRI_M |
| INRNEMOSEPIN_MAIPSAC_SES_LN_ANEIISUNTINU |
| _AR_TM_UMOECNU_RIREIAL_AEFIITP |
|
| (a) First approximation to ? |
| CT_QU_VENINLUM_UA_QUREO_ABIT_SAT_FIUMA |
| GE_ICAM_MESTAM_M_QUM_CUTAT_PAM_NOND |
| QUM_O_M_FIT_NISERIST_E_L_ONO_IHOSEROCO |
|
| (b) Second approximation to ? |
| ET_LIGERCUM_SITECI_LIBEMUS_ACERELEN_TE |
| _VICAESCERUM_PE_NON_SUM_MINUS_UTERNE |
| _UT_IN_ARION_POPOMIN_SE_INQUENEQUE_IRA |
|
| (c) Third approximation to ? |
| Figure 2-15. A series of approximations to ? |
NOTES
Note 4. In addition to generating words of a language from an artificial
source, as illustrated in Section 2-8, it is possible to generate musical compositions.
Pinkerton (1956) has used this method of musical composition. Pierce (1961)
devotes several pages to the generation of such music; perhaps the ultimate
in artistic information theory is displayed in some passages from the
"Illiac Suite for String Quartet" reproduced in Pierce (1957, p. 260).
References
Pierce, J. R. (1961): "Symbols, Signals and Noise," Harper & Row, Publishers, Incorporated, New York.
Pinkerton, R. C. (1956):Information Theory and Melody, Sci. Am., pp. 77-87, February.
Pratt, F. (1942): "Secret and Urgent," Doubleday & Company, Inc., Garden City, N.Y.
Reza, F. M. (1961): "An Introduction to Information Theory," McGraw-Hill Book Company, Inc., New York.
The above is section 2-8, pp 33-40, from the book INFORMATION THEORY AND CODING by Norman Abramson,
Associate Professor of Electrical Engineering, Stanford University.
McGraw-Hill Book Company, Inc. 1963 McGraw-Hill electronic Sciences Series.