How Computers Generate Random Numbers - Chapter 1

Consider the case of rolling a single die. A theoretician picks up the
die, examines it, and makes the following statement: "The die has six
sides, each side is equally likely to turn up, therefore the
probability of any one particular side turning up is 1 out of 6 or 1/6.
Furthermore, each throw of the die is completely independent of all
previous throws." With that the theoretician puts the die down and
leaves the room without ever having thrown it once.
An experimentalist, never content to accept what a cocky theoretician
states as fact, picks up the die and starts to roll it. He rolls the
die a number of times, and carefully records the results of each throw.
Let us first dispel the myth that there is such a thing as an ideal
sequence of random numbers. If the experimentalist threw the die 6
times and got 6 "one"s in a row, he would be very upset at the die. If
the same experimentalist threw the same die a billion times in a row and
never got 6 "one"s in a row, he would again be very upset at the die.
The fact is a truly random sequence will exhibit local nonrandomness.
Therefore, a subsequence of a sequence of random numbers is not
necessarily random. We are forced to conclude that no one sequence of
"random" numbers can be adequate for every application.
Before we can analyze the resulting data the theoretician collected, we
must first review the language of probability theory and the underlying
mathematics.
A single throw of the die is called a "chance experiment" and is
designated by the capital letter E. An outcome of a chance experiment
E is designated by the Greek letter zeta
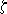 .
If there is more than one
possible outcome of the chance experiment, (as there always will be,
else the analysis becomes trivial), the different possible outcomes
of the chance experiment are designated by
.
If there is more than one
possible outcome of the chance experiment, (as there always will be,
else the analysis becomes trivial), the different possible outcomes
of the chance experiment are designated by
 ,
,
 ...
The set of all possible outcomes of a chance experiment is called the
"Universal Set" or "Sample Space", and is denoted by the capital
letter S.
...
The set of all possible outcomes of a chance experiment is called the
"Universal Set" or "Sample Space", and is denoted by the capital
letter S.
For the die throwing experiment E, we have:
Chance experiment:
E: one throw of the die
Possible outcomes:
=

side with one dot ends facing up
=

side with two dot ends facing up

=

side with three dot ends facing up

=

side with four dot ends facing up

=

side with five dot ends facing up

=

side with six dot ends facing up
Sample Space (or Universal Set):
We now define the concept of a "random variable". A random variable is
a function which maps the elements of the sample space S to points on
the real number line RR. This is how we convert the outcomes of a
chance experiment E to numerical values. The random variable function
is denoted by a capital X. An actual value a random variable X takes
on is denoted by a lowercase x.
A natural random variable function X to define for the die rolling
experiment is:
X(
) = 1.0
X(
) = 2.0
X(
) = 3.0
X(
) = 4.0
X(
) = 5.0
X(
) = 6.0
Note that the faces of a standard die are marked with this random
variable function X in mind. The number of dots showing on the top
face of the die corresponds to the value the function X takes on for
that particular outcome of the experiment.
We now consider the generation of a random sequence of numbers
by repeating a chance experiment E a number of times. This can be
thought of as a single n-fold compound experiment, which can be
designated by:
| E x E x . . . x E |
= En |
| (N times) | |
The sample space or universal set of all possible outcomes for our
compound experiment En is the Cartesian product of the sample spaces
for each individual experiment E:
| Sn = | S x S x . . . x S |
| | (N times) |
Any particular result of a compound experiment En will be an ordered
set of elements from set S. For example, if E is the die throwing
experiment, then the elements of set Sn for rolling the die N times are:
| Sn = { | { |
, |
, |
, |
, |
, |
|
}, |
| | { |
, |
, |
, |
, |
, |
|
}, |
| | { |
, |
, |
, |
, |
, |
|
}, |
| | |
. |
. |
. |
. |
. |
. |
|
| | |
. |
. |
. |
. |
. |
. |
|
| | |
. |
. |
. |
. |
. |
. |
|
| | { |
, |
, |
, |
, |
, |
|
} } |
The total number of elements in Sn is equal to the number of elements
in S raised to the Nth power. For the die throwing experiment, there
are 6 possible outcomes for the first throw, 6 possible outcomes for
the second throw, etc. so the total number of possible outcomes for
the compound experiment En is:
| 6 * 6 * . . . * 6 | = 6**N = |Sn| |
| (N times) | |
The probability of any particular element in Sn is equal to the product
of the probabilities of the corresponding elements from S which
together comprise the element in Sn. If each element of S is equally
likely, then each element of Sn is equally likely. Which translated
means if each possible outcome of experiment E is equally likely, then
each possible outcome of experiment En is equally likely. For our die
throwing experiment, each of the 6 possible outcomes for throwing the
die once is equally likely, so each of the 6**N possible outcomes for
throwing the die N times is equally likely.
We can now take our random variable function X and apply it to each of
the N outcomes from our compound experiment En. This is how we convert
the outcome of experiment En into an ordered set of N random variables:
( X1, X2, ..., Xn )
In this way each specific element of our sample space Sn can be
transformed into a set of n ordered real values. We will use a
lowercase letter x to denote specific values that a random variable
function X takes on. So the results of a specific compound experiment
En when transformed into specific real values would look something
like this:
( x1, x2, ..., xn )
For example, if we rolled a die N times we might get the result:
| ( 3, 5, 2, 6, ..., 4 ) |
| (N times) |
Then again, if we rolled a die N times we might get the result
consisting of all ones:
| ( 1, 1, 1, 1, ..., 1 ) |
| (N times) |
The first result looks somewhat like what we would expect a sequence of
random numbers to be. The second result consisting of all ones however
tends to make us very unhappy. But, and here is the crux, each
particular outcome is equally likely to occur! Each outcome
corresponds to a particular element in Sn, and each element in Sn has
an equal probability of occurring. We are forced to conclude that ANY
sequence of random numbers is as equally likely to occur as any other.
But for some reason, certain sequences make us very unhappy, while
other sequences do not.
We are forced to conclude, therefore, that our idea of a good sequence
of random numbers is more than just anything you might get by
repeatedly performing a random experiment. We wish to exclude certain
elements from the sample space Sn as being poor choices for a sequence
of random numbers. We accept only a subspace of Sn as being good
candidates for a sequence of random numbers. But what is the
difference between a good sequence of random numbers and a bad sequence
of random numbers?
For our die rolling experiment, if we believe the die to be fair, and
roll the die N times, then we know all possible sequences of N outcomes
are equally likely to occur. However, only a subset of those possible
outcomes will make us believe the die to be fair. For example, the
sequence consisting of all ones {1,1,...,1} is as equally likely to
occur as any other sequence, but this sequence tends not to reinforce
our assumption that the die is fair. A good sequence of random numbers
is one which makes us believe the process which created them is random.