Many computer programming languages today include a function for generating random numbers. For example, the C programming language includes a function named rand() as a standard part of its language. Supposedly once you get the generator going by giving it a "seed" value then all you have to do is call it repeatedly and it will give you a "random" number every time. But how is it that computers, which are completely deterministic machines, can generate "random" numbers?
This paper presents some background theory in basic probability theory and inferential statistics. We then present a number of empirical tests for analyzing a computer generated sequence of random numbers, and we apply these tests to several popular random number generators.
Consider the case of rolling a single die. A theoretician picks up the die, examines it, and makes the following statement: "The die has six sides, each side is equally likely to turn up, therefore the probability of any one particular side turning up is 1 out of 6 or 1/6. Furthermore, each throw of the die is completely independent of all previous throws." With that the theoretician puts the die down and leaves the room without ever having thrown it once.
An experimentalist, never content to accept what a cocky theoretician states as fact, picks up the die and starts to roll it. He rolls the die a number of times, and carefully records the results of each throw.
Let us first dispel the myth that there is such a thing as an ideal sequence of random numbers. If the experimentalist threw the die 6 times and got 6 "one"s in a row, he would be very upset at the die. If the same experimentalist threw the same die a billion times in a row and never got 6 "one"s in a row, he would again be very upset at the die. The fact is a truly random sequence will exhibit local nonrandomness. Therefore, a subsequence of a sequence of random numbers is not necessarily random. We are forced to conclude that no one sequence of "random" numbers can be adequate for every application.
Before we can analyze the resulting data the theoretician collected, we must first review the language of probability theory and the underlying mathematics.
A single throw of the die is called a "chance experiment" and is
designated by the capital letter E. An outcome of a chance experiment
E is designated by the Greek letter zeta
![]() .
If there is more than one
possible outcome of the chance experiment, (as there always will be,
else the analysis becomes trivial), the different possible outcomes
of the chance experiment are designated by
.
If there is more than one
possible outcome of the chance experiment, (as there always will be,
else the analysis becomes trivial), the different possible outcomes
of the chance experiment are designated by
![]() ,
,
![]() ...
The set of all possible outcomes of a chance experiment is called the
"Universal Set" or "Sample Space", and is denoted by the capital
letter S.
...
The set of all possible outcomes of a chance experiment is called the
"Universal Set" or "Sample Space", and is denoted by the capital
letter S.
For the die throwing experiment E, we have:
Chance experiment:
Sample Space (or Universal Set):
We now define the concept of a "random variable". A random variable is a function which maps the elements of the sample space S to points on the real number line RR. This is how we convert the outcomes of a chance experiment E to numerical values. The random variable function is denoted by a capital X. An actual value a random variable X takes on is denoted by a lowercase x.
A natural random variable function X to define for the die rolling experiment is:
Note that the faces of a standard die are marked with this random variable function X in mind. The number of dots showing on the top face of the die corresponds to the value the function X takes on for that particular outcome of the experiment.
We now consider the generation of a random sequence of numbers by repeating a chance experiment E a number of times. This can be thought of as a single n-fold compound experiment, which can be designated by:
| E x E x . . . x E | = En |
| (N times) |
The sample space or universal set of all possible outcomes for our compound experiment En is the Cartesian product of the sample spaces for each individual experiment E:
| Sn = | S x S x . . . x S |
| (N times) |
Any particular result of a compound experiment En will be an ordered set of elements from set S. For example, if E is the die throwing experiment, then the elements of set Sn for rolling the die N times are:
| Sn = { | { | }, | ||||||
| { | }, | |||||||
| { | }, | |||||||
| . | . | . | . | . | . | |||
| . | . | . | . | . | . | |||
| . | . | . | . | . | . | |||
| { | } } |
The total number of elements in Sn is equal to the number of elements in S raised to the Nth power. For the die throwing experiment, there are 6 possible outcomes for the first throw, 6 possible outcomes for the second throw, etc. so the total number of possible outcomes for the compound experiment En is:
| 6 * 6 * . . . * 6 | = 6**N = |Sn| |
| (N times) |
The probability of any particular element in Sn is equal to the product of the probabilities of the corresponding elements from S which together comprise the element in Sn. If each element of S is equally likely, then each element of Sn is equally likely. Which translated means if each possible outcome of experiment E is equally likely, then each possible outcome of experiment En is equally likely. For our die throwing experiment, each of the 6 possible outcomes for throwing the die once is equally likely, so each of the 6**N possible outcomes for throwing the die N times is equally likely.
We can now take our random variable function X and apply it to each of the N outcomes from our compound experiment En. This is how we convert the outcome of experiment En into an ordered set of N random variables:
In this way each specific element of our sample space Sn can be transformed into a set of n ordered real values. We will use a lowercase letter x to denote specific values that a random variable function X takes on. So the results of a specific compound experiment En when transformed into specific real values would look something like this:
For example, if we rolled a die N times we might get the result:
| ( 3, 5, 2, 6, ..., 4 ) |
| (N times) |
Then again, if we rolled a die N times we might get the result consisting of all ones:
| ( 1, 1, 1, 1, ..., 1 ) |
| (N times) |
The first result looks somewhat like what we would expect a sequence of random numbers to be. The second result consisting of all ones however tends to make us very unhappy. But, and here is the crux, each particular outcome is equally likely to occur! Each outcome corresponds to a particular element in Sn, and each element in Sn has an equal probability of occurring. We are forced to conclude that ANY sequence of random numbers is as equally likely to occur as any other. But for some reason, certain sequences make us very unhappy, while other sequences do not.
We are forced to conclude, therefore, that our idea of a good sequence of random numbers is more than just anything you might get by repeatedly performing a random experiment. We wish to exclude certain elements from the sample space Sn as being poor choices for a sequence of random numbers. We accept only a subspace of Sn as being good candidates for a sequence of random numbers. But what is the difference between a good sequence of random numbers and a bad sequence of random numbers?
For our die rolling experiment, if we believe the die to be fair, and roll the die N times, then we know all possible sequences of N outcomes are equally likely to occur. However, only a subset of those possible outcomes will make us believe the die to be fair. For example, the sequence consisting of all ones {1,1,...,1} is as equally likely to occur as any other sequence, but this sequence tends not to reinforce our assumption that the die is fair. A good sequence of random numbers is one which makes us believe the process which created them is random.
Up until now we have been dealing with probability theory. We started with a chance experiment in which the probability of each result is given, and then worked our way forward to find out what the probability of a particular compound experiment would be. We now turn to the field of inferential statistics, where we attempt to do the reverse. Given a sequence of numbers created by N trials of a chance experiment, we attempt to work our way backwards and estimate what the defining properties of the chance experiment are.
For our die throwing experiment, we would like to estimate the
probability of each outcome based on experimental data. If we throw
the die N times, then the best estimate we could make for the
probability of a particular outcome ![]() would be to count the number
of times
would be to count the number
of times ![]() occurred in N trials and form the ratio:
occurred in N trials and form the ratio:
If we define a frequency function f(![]() ) to be the number of times
) to be the number of times
![]() occurred in N trials, we then would have:
occurred in N trials, we then would have:
This is our estimate of the probability of ![]() based on N trials of the
chance experiment. Note that some people use this equation as the
definition for the probability of an event
based on N trials of the
chance experiment. Note that some people use this equation as the
definition for the probability of an event ![]() when N goes to infinity:
when N goes to infinity:
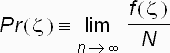
For our die throwing experiment, assume we want to estimate the
probability of ![]() , (the side with one dot shows up). Say we throw
the die 6 times, and out of those 6 times
, (the side with one dot shows up). Say we throw
the die 6 times, and out of those 6 times ![]() occurred twice. We
then calculate the probability of
occurred twice. We
then calculate the probability of ![]() as 2/6.
as 2/6.
We now have the problem of deciding which value to accept as correct, and how much faith we can place on our choice. Let us define two possible hypotheses, which we will denote as H0 and H1.
In choosing which hypothesis to believe, there are two possible errors we could make, known as a type I error and a type II error:
We can determine the probability of making each type of error by
examining the theoretical probability distributions for f(![]() )
for each hypothesis being tested.
)
for each hypothesis being tested.
We rolled the die six times, so the possible number of times ![]() can
occur is between 0 and 6 times. Let f(
can
occur is between 0 and 6 times. Let f(![]() ) be the number of times
) be the number of times
![]() occurred in six rolls of the die. The following binomial
formula will calculate the probability of having
occurred in six rolls of the die. The following binomial
formula will calculate the probability of having ![]() occur k times
in n trials:
occur k times
in n trials:
With n = 6 trials, and assuming hypothesis H0 to be true (the
probability of throwing ![]() is 1/6), we obtain the following table:
is 1/6), we obtain the following table:
| f( | Pr ( f( | sideways bar graph | ||
|---|---|---|---|---|
| 0 | 0.334897 | |================ | ||
| 1 | 0.401877 | |==================== | ||
| 2 | 0.200938 | |========== | ||
| 3 | 0.053583 | |== | ||
| 4 | 0.008037 | | | ||
| 5 | 0.000643 | | | ||
| 6 | 0.000021 | | |
As you can see from the numbers, the highest probability is for
throwing one ![]() , although there is still a high probability for
throwing zero or two
, although there is still a high probability for
throwing zero or two ![]() 's. If we repeat the binomial calculations
this time assuming hypothesis H1 is true (the probability of
's. If we repeat the binomial calculations
this time assuming hypothesis H1 is true (the probability of ![]() is
2/6), we arrive at the following slightly different table:
is
2/6), we arrive at the following slightly different table:
| f( | Pr ( f( | sideways bar graph | ||
|---|---|---|---|---|
| 0 | 0.087791 | |==== | ||
| 1 | 0.263374 | |============= | ||
| 2 | 0.329218 | |================ | ||
| 3 | 0.219478 | |========== | ||
| 4 | 0.082304 | |==== | ||
| 5 | 0.016460 | |= | ||
| 6 | 0.001371 | | |
We can now calculate the probability of making a type I error and of making a type II error.
From these two formulas and the tables above we can now calculate the probability of making a type I error and a type II error.
| Pr(M|H0) | = | probability of rolling |
| = | 0.200938 (from table above) |
| Pr(M|H1) | = | probability of rolling |
| when probability of rolling | ||
| = | 0.329218 (from table above) |
| Pr( type I error ) | = | Pr(H0|M) | = | |
| = | ||||
| = | 0.379 | |||
| Pr( type II error ) | = | Pr(H1|M) | = | |
| = | ||||
| = | 0.621 | |||
In this case we have a 38% chance of being wrong if we choose to
believe Pr(![]() ) = 2/6 and a 62% chance of being wrong if we choose
to believe Pr(
) = 2/6 and a 62% chance of being wrong if we choose
to believe Pr(![]() ) = 1/6. Either way we're likely to be wrong. The
data does not allow us to differentiate between the two possibilities
with much confidence.
) = 1/6. Either way we're likely to be wrong. The
data does not allow us to differentiate between the two possibilities
with much confidence.
Let us repeat the above calculations this time assuming we rolled
![]() five out of six times. This would lead us to the estimate that
Pr(
five out of six times. This would lead us to the estimate that
Pr(![]() ) = 5/6. Let us create a new hypothesis:
) = 5/6. Let us create a new hypothesis:
| f( | Pr ( f( | sideways bar graph | ||
|---|---|---|---|---|
| 6 | 0.001371 | | | ||
| 0 | 0.000021 | | | ||
| 1 | 0.000430 | | | ||
| 2 | 0.008037 | | | ||
| 3 | 0.053583 | |== | ||
| 4 | 0.200938 | |========== | ||
| 5 | 0.401877 | |==================== | ||
| 6 | 0.334897 | |================ |
Following the same procedure as above:
| Pr( type I error ) | = | Pr(H0|M) | = | |
| = | ||||
| = | 0.001 | |||
| Pr( type II error ) | = | Pr(H1|M) | = | |
| = | ||||
| = | 0.998 | |||
In this case, given a choice between believing the theoretician who
claims Pr(![]() ) = 1/6 and believing our own tests which claim
Pr(
) = 1/6 and believing our own tests which claim
Pr(![]() ) = 5/6, if we choose to believe the theoretician we have a
99.8% chance of being wrong, and if we choose to believe our own
experimental results we have a 0.1% chance of being wrong. Clearly the
odds are in favor of our being right. And we only threw the die six
times!
) = 5/6, if we choose to believe the theoretician we have a
99.8% chance of being wrong, and if we choose to believe our own
experimental results we have a 0.1% chance of being wrong. Clearly the
odds are in favor of our being right. And we only threw the die six
times!
This then is why a sequence consisting of all ones { 1, 1, ..., 1 } is unlikely to be from a compound experiment in which each outcome is equally likely. If we hypothesize that each outcome is equally likely (hypothesis H0), then all elements in our sample space Sn do have an equal probability. But if we conjure up an alternative hypothesis about the probability of outcomes (hypothesis H1), then all the elements in our sample space Sn no longer have an equal probability. The probability will be higher for some elements and lower for other elements. Our hypothesis H1 is specifically formulated to give whatever sequence we actually got the highest probability possible. If the resulting probability of our sequence occurring under our original H0 hypothesis is very low, then it's almost for certain that it will loose out under an alternate hypothesis H1. Thus if all we want to do is test whether or not to reject our original H0 hypothesis, all we need to do is see what the probability of our sequence occurring under our original H0 hypothesis is. If it is very low, we can reject our H0 hypothesis under the implied knowledge that a better hypothesis H1 probably exists. We don't actually have to formulate a better hypothesis H1, we just have to know that we could make one if we cared to.
Thus from here on out we won't go the whole distance of formulating an alternative hypothesis H1 and then calculating the probabilities of type I errors and type II errors. We'll just say if an actual outcome of a compound experiment has a very low probability of occurring under our H0 hypothesis (or null hypothesis), then that hypothesis is probably not true.
| 1. | Formulate a null hypothesis H0 about the single chance experiment which was repeated N times to create a sequence of N values. To test a sequence of supposedly random numbers, our null hypothesis H0 is that each outcome of the chance experiment is equally likely, and that each trial of the chance experiment is independent of all previous trials. | |||
| 2. | Formulate a real valued function g which somehow tests the null hypothesis H0. To test a sequence of supposedly random numbers, our function g might be one which counts the number of occurrences of a particular outcome. | |||
| 3. | Under our null hypothesis H0, mathematically define a sequence of N random variables: | |||
| ( X1, X2, ..., Xn ) | ||||
| and apply our function g to the sequence of N random variables creating a new random variable Z: | ||||
| Z = g | ( X1, X2, ..., Xn ) | |||
| Then determine the probability density function of Z either by mathematical calculations or by finding a table of the particular probability density function we're interested in. | ||||
| 4. | Take the specific sequence of values supposedly obtained by performing a chance experiment N times: | |||
| ( x1, x2, ..., xn ) | ||||
| and apply the function g to obtain a specific value z | ||||
| z = g | ( x1, x2, ..., xn ) | |||
| 5. | Determine from the probability density function of Z how likely or unlikely we are to obtain our value of z assuming our null hypothesis H0 is true. If the probability is very low, we may reject our hypothesis H0 as being most likely incorrect. | |||
We come now to our first real test for a sequence of random numbers.
The test is the ![]() (Chi-Square, pronounced ki-square) test. It tests the assumption
that the probability distribution for a given chance experiment is as
specified. For our die throwing experiment, it tests the probability
that each possible outcome is equally likely with a probability of 1/6.
The formula for our
(Chi-Square, pronounced ki-square) test. It tests the assumption
that the probability distribution for a given chance experiment is as
specified. For our die throwing experiment, it tests the probability
that each possible outcome is equally likely with a probability of 1/6.
The formula for our ![]() g function is:
g function is:
| N | = | number of trials |
| k | = | number of possible outcomes of the chance experiment |
| f( | = | number of occurrences of |
| E( | = | The expected number of occurrences of |
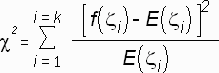 | ||
We now go through the steps as defined above:
| 1. | Formulate the null hypothesis H0. Our null hypothesis H0 for the die throwing experiment is that each of the six possible outcomes is equally likely with a probability of 1/6. |
| 2. | Formulate a real valued function g which somehow tests the null
hypothesis. Our g function is the |
| 3. | Determine the probability density function of Z = g(X1,X2,...Xn).
As mentioned in step 2, our |
| Each row of the | |
| Below is the | |
| p=1% | p=5% | p=25% | p=50% | p=75% | p=95% | p=99% | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.5543 | 1.1455 | 2.675 | 4.351 | 6.626 | 11.07 | 15.09 |
| (Note: See NUMERICAL RECIPES: The Art of Scientific Computing listed in the references for computer code that will calculate | |
| This is the cumulative | |
| (Note that some tables list the probability for (1 - p) instead of p, so that 0.5543 is listed as p=99% instead of p=1%, and 15.09 is listed as p=1% instead of p=99%. It should be easy to tell by inspection which probability the table is listing.) | |
| 4. | We can now apply our |
| f( | |
| f( | |
| f( | |
| f( | |
| f( | |
| f( | |
| Then our | |
| = 3.2 | |
| 5. | We can now check our result of 3.2 against the |
Further notes on ![]() :
:
| Note that not only are overly large values of |
| As an example, if we threw a single die 6 times, there would be 6**6
or 46656 possible outcomes. If we calculate the |
| f( | ||
|---|---|---|
| ------ | --------- | |
| 0 | 720 | |
| 2 | 10800 | |
| 4 | 16200 | |
| 6 | 9000 | |
| 8 | 7200 | |
| 12 | 2100 | |
| 14 | 450 | |
| 20 | 180 | |
| 30 | 6 |
| Although a |
| Another note about the |
| given: | |
| Z = | 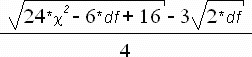 |
| Here Z is a normally distributed variable with mean = 0 and
variance = 1. As an example, let's assume we are simulating
the random choosing of a single card from a deck of 52. There
are 52 possible outcomes. We will need to repeat this
experiment 52*5=260 times so that each possible outcome occurs
about 5 times. Our number of degrees of freedom is 52 - 1 = 51.
We calculate | |
| Z = | |
| = | -2.33 |
| We now look up in a table of the cumulative normal distribution
and find this value of Z corresponds to the first 1% of the
distribution. Thus our | |
| One last note about |
If we repeat the die throwing experiment 30 times, we can perform one
![]() test on the results. If we repeat the die throwing
experiment 3000 times, we can either perform one
test on the results. If we repeat the die throwing
experiment 3000 times, we can either perform one ![]() test to get
an idea of the long term probabilities of each possible outcome, or we
can perform 300
test to get
an idea of the long term probabilities of each possible outcome, or we
can perform 300 ![]() tests for each block of 30 trials to get an
idea of the relative short term fluctuations. In the latter case, we
would expect the distribution of our 300
tests for each block of 30 trials to get an
idea of the relative short term fluctuations. In the latter case, we
would expect the distribution of our 300 ![]() tests to approach
the
tests to approach
the ![]() distribution.
distribution.
This brings us to our next subject, which is testing a set of data
points to see how closely it matches a given continuous distribution.
The Kolmogorov-Smirnov (KS) test compares a set of nc data points Snc
(e.g. set of a number of ![]() data points) with a given
cumulative distribution function P(x) (e.g. the
data points) with a given
cumulative distribution function P(x) (e.g. the ![]() cumulative
distribution).
cumulative
distribution).
Given a set of nc data points Snc, we can create a cumulative distribution function Snc(x) from the data points. The function will be a step function, rising from 0 to 1, with each step size equal to 1/nc. Below is a generalized example which compares a cumulative distribution step function Snc(x) for 9 data values against a continuous cumulative distribution P(x) for a function which is uniform between 0 and 1:

Kolmogorov-Smirnov statistic D. A measured distribution of values in x (
shown as N dots on the lower abscissa) is to be compared with a theoretical distribution whose
cumulative probability distribution is plotted as P(x). A step-function cumulative
probability distribution Snc(x) (labeled |
The KS test is now very simple. Define D as the maximum vertical difference between these two functions:
We can then go directly to a table for the KS test (similar to the
![]() table), and read off where in the cumulative distribution
our DQ value lies, remembering that values below p=5% only occur 5% of
the time, and values above p=95% only occur 5% of the time. Tables for
this KS test are not as easy to find as tables for the
table), and read off where in the cumulative distribution
our DQ value lies, remembering that values below p=5% only occur 5% of
the time, and values above p=95% only occur 5% of the time. Tables for
this KS test are not as easy to find as tables for the ![]() test.
Fortunately, as in the
test.
Fortunately, as in the ![]() case, if our number of data values nc
in set Snc is greater than 30, the distribution approaches something
which can be easily calculated as follows:
case, if our number of data values nc
in set Snc is greater than 30, the distribution approaches something
which can be easily calculated as follows:
| Given: | D = max |Snc(x) - P(x)| |
| nc > 30 (number of data points) |

| Introduction | Chapter 3 | |||||
index | ||||||
Back to Deley's Homepage | ||||||