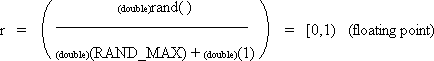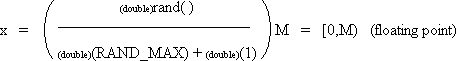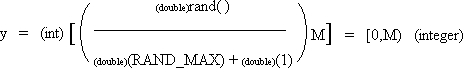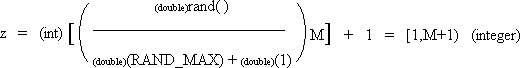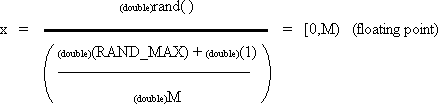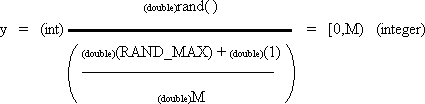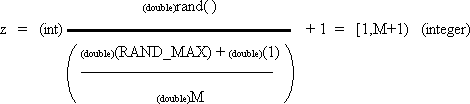| | int seed; | |
/* Choose any integer value for seed to
initialize the random number generator with.
The same value of seed will always produce
the same sequence of random numbers. To get
a different sequence of random numbers next
time, choose a different value of seed. |
|
|
Note: on Microsoft Visual C++ 6.0, if seed
is negative then a seed value from the
system clock is used. Also check for a
randomize() function on your compiler. */ |
|
| double r; | | /* random value in range [0,1) */ |
|
| long int M; | | /* user supplied upper boundary */ |
|
| double x; | | /* random value in range [0,M) */ |
| int y; | | /* random integer in range [0,M) if M is an integer then range = [0,M-1] */
|
| int z; | | /* random integer in range [1,M+1) if M is an integer then range = [1,M] */ |
| int count; | | /* just a variable we need to count how many random numbers we've made for this example */ |
| /*BEGIN CODE*/ |
| seed = 10000; | | /* choose a seed value */ |
| srand(seed); | | /*initialize random number generator*/ |
|
| M = 1000; | | /* Choose M. Upper bound. (M should be much less than RAND_MAX. See below.) */ |
For y if M is an integer then the result is between 0 and M-1 inclusive.
For z if M is an integer then the result is between 1 and M inclusive.
[Note from Bret, 2008-09-14]: Technically, this isn't necessarily true. The standard only
indicates that rand() is required to
return at least 15 bits of useful
data at a time. It does not mandate that the internal state of rand() is only
15 bits. Even if you generate RAND_MAX - 1 values, you cannot predict what
the next value will be if rand() has an internal state that is more than 15
bits.
For example, an ANSI-compliant
library could implement rand() using Mersenne Twister which has a
period of 2^19937-1, but still only return [0, 32767] from rand()
simply by masking off the lower 15 bits from each value that it
generates.
The main problem with rand() is that it could be using only 15
bits of state and therefore could be repeating itself every 32768
values. The standard doesn't require anything better than that, and many
implementations of it are of poor quality. That's why it has been superceded
by random() which is more explicit about how it is
implemented. So the rule-of-thumb I would recommend is "don't use it".
If you're stuck with it, one way to enhance the range but still avoid the
"gaps" problem you mentioned would be to do something like this:
Calling rand() four times gives
you at least 60 bits of info, which is enough to saturate the
precision of double (53 bits in the mantissa). It's still not
recommended, though.
If you want to avoid using slow
floating-point calculations but still avoid the problem with using "%"
to generate an integer sub-range, you could scale the integer range up
to make it as close to RAND_MAX as possible, repeatedly call rand()
until you get a value less than the scaled-up range, and then scale the
result back down. If the range is greater than RAND_MAX you can do the
same thing up to RAND_MAX * RAND_MAX with numbers generated with rand()
* (RAND_MAX+1) + rand().
Pseudo-code:
int range = max - min;
if (range < RAND_MAX)
{
int scale = (RAND_MAX + 1) / range;
int scaledRange = scale * range;
while (true)
{
int r = rand();
if (r < scaledRange) return r / scale + min;
}
}
int RAND_MAX_2 = (RAND_MAX + 1) * (RAND_MAX + 1) - 1;
if (range < RAND_MAX_2)
{
int scale = (RAND_MAX_2 + 1) / range;
int scaledRange = scale * range;
while (true)
{
int r = rand() * (RAND_MAX + 1) + rand();
if (r < scaledRange) return r / scale + min;
}
}
That second half only works if
RAND_MAX_2 fits within the size of int, which it usually won't if
RAND_MAX > 65535.